

Throughout the 80’s, and 90’s Systems Administrators (or SysAdmins) wrote code to create, improve, and manage the computing systems under their domains and it worked reasonably well for the environments and needs of the time.
Systems grew and became more complex requiring more and more moving parts (virtual or otherwise) and specializations were created and evolved to handle this.
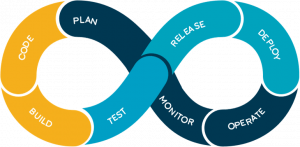
DevOps is a methodology of continuous change control to streamline processes from Software Development through Testing and Validation and deployments into Production.
It is a lifecycle process of continuous improvements to ensure reliable changes.
Google vice president of engineering Ben Treynor Sloss coined the term SRE back in the early 2000s. He defined it as: “It’s what happens when you ask a software engineer to design an operations function.”
Image source: Splunk + VictorOps
Site Reliability Engineering is a branch of engineering focused on reliability of systems, services, and products. Uptime, Resource Utilization, and Forecasting, System Reliability, Change Control, Systems Integration are all at the forefront and concerns of SRE.
Site reliability engineers (SREs) bridge the gap between development and operations by applying the mindsets of both disciplines to ensure feature development with an appropriate level of security, reliability, scalability, and performance.
SREs are focused on the holistic view from software delivery to monitoring to incident response that improves service resiliency without sacrificing development turnaround time.
An SRE team that is prepared monitors the service’s health and responds effectively during problems. Resources that will help the team understand the entire system especially during troubleshooting. A well-defined incident management with dashboards and metrics will build foundation for a prepared team.
You can find out more about DevOps, SRE, and how Crest Data Systems can help bring those services into your organization from the following links.

Richard McIntosh is a Technical Operations and SRE Lead at Crest Data Systems with 25+ years of industry experience working on High Performance Computing, Cloud Computing, DevOps, and Technology & Security management. Before joining Crest, Richard worked for other small to large enterprise companies in the defense, entertainment, and the semiconductor industry.