

A search head is used to – as the name suggests –search the data. Search heads get all the traffic from the end users. End users log into the UI using the search head and run their searches, reports, alerts, and dashboards and other knowledge objects.
Depending on the use case for the data and infrastructure which decide role for selecting the type of forwarder. To learn more about the difference refer this link.
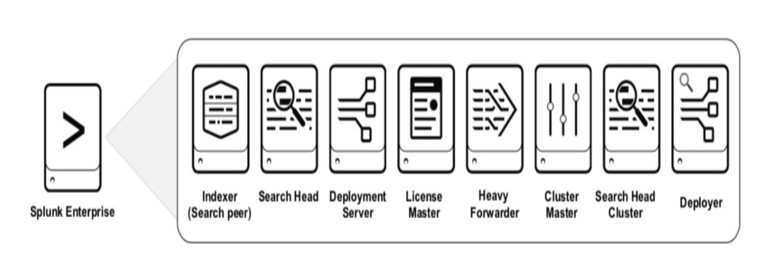
Components above are represented diagrammatically as follows:
When is this deployment type used?
This type of deployment is typically used when there are a limited number of users and a very limited amount of data flowing into Splunk.
Component | Pros | Cons |
Supportability | Very easy to manage and support as it has only one instance | NA |
High Availability | NA | No high availability as it is a single point of failure |
Disaster Recovery | NA | No disaster availability as it is a single point of failure |
Search Concurrency | NA | Low search concurrency as it is a single instance and can be over-loaded easily |
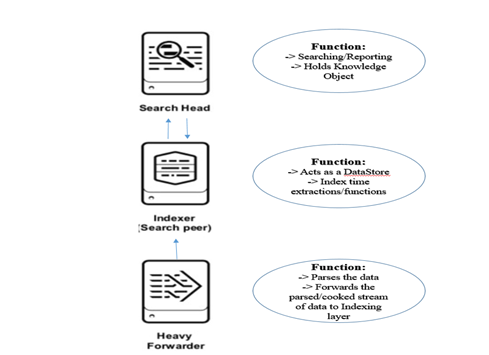
Component | Pros | Cons |
Supportability | Easy to support as the components are separated out in different functions | NA |
High Availability | NA | Single point of failure. If the indexer goes down, then indexing stops. |
Disaster Recovery | NA | Single point of failure. |
Search Concurrency | Higher search concurrency compared to standalone as Search head is separated out | If the users are more, consider going into search head clustering for higher search concurrency |
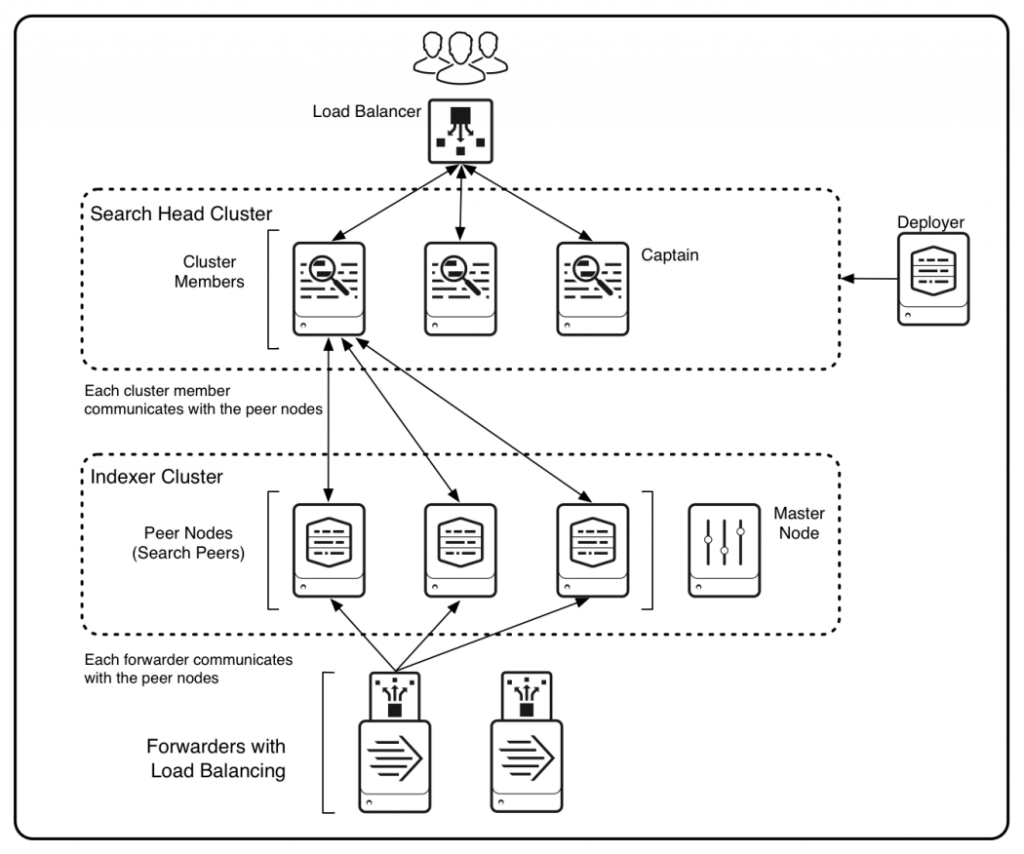
(Image source: Splunk)
Component | Pros | Cons |
Supportability | Supportaibility is challenging, however, with Master and Captain Nodes we can manage the Splunk configs and apps easily | NA |
High Availability | Highly Available as data is replicated across multiple nodes and if single indexer goes down still the data is searchable. If a search head goes down, other search heads will continue to provide the service | NA |
Disaster Recovery | No disaster recovery | No disaster recovery |
Search Concurrency | High search concurrency as there is a cluster of Search Heads serving multiple customers | NA |

Jeet Thakkar is working as a Splunk Professional Services Consultant at Crest Data Systems for 3+ years. As a senior consultant, Jeet specializes in understanding requirements and building Security and ITOps use cases for the customers. He has experience handling complex Splunk deployments with multi-terabyte Splunk licenses for Fortune 500 companies. Jeet is currently working on building DevOps solutions using technologies like Terraform, Ansible, Jenkins, and Kubernetes.