

Several customers start their Splunk POC deployment as a standalone OR single instance deployment. Once the POC is done, scaling it from a stand-alone instance is crucial to be production-ready. One of the major challenges is the migration of data.
There is no standard procedure for data migration. The cluster needs to create multiple searchable and non-searchable copies of the buckets to fulfill the cluster’s replication factor (RF) and search factor (SF), which will take huge amount of time and processing based on the size of the data.
Buckets available on the indexer prior to its being added to the cluster are called “standalone” buckets. These buckets do not get replicated because the cluster does not replicate any buckets that are already on the indexer. However, searches will still occur across those buckets and will be combined with the search results from the cluster’s replicated buckets.
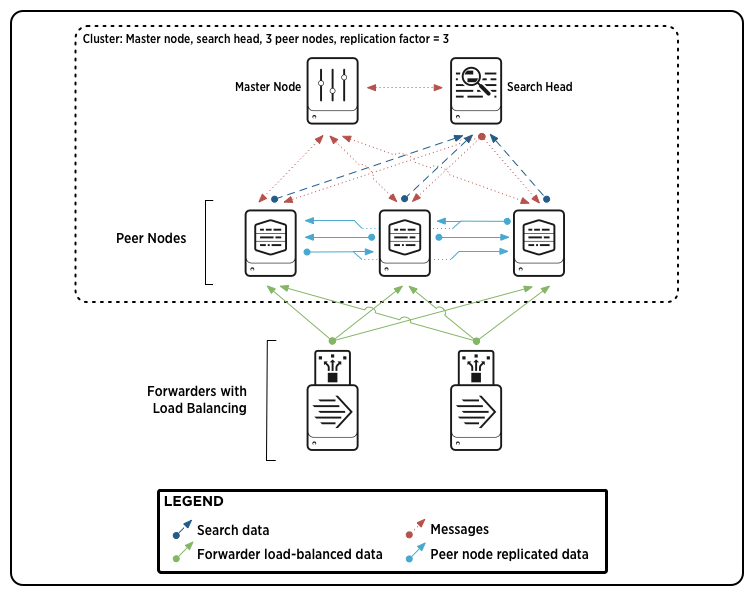
Image Source: Splunk
To migrate data, it is not advisable to add the ‘standalone’ instance to the cluster. It is advisable to create a new Indexer cluster and copying the cluster with the data and the configs. This will always ensure backup in case the data migration process fails.
Few things to keep in mind before migrating from standalone instance to Cluster environment:
Where,
latesttime is the timestamp of the latest event in the bucket
earliesttime is the timestamp of the earliest event in the bucket
idnum is unique bucket ID number GUID is the GUID of the indexer where bucket resides/originated – this can be found in $SPLUNK_HOME/etc/instance.cfg
GUID is the GUID of the indexer where bucket resides/originated. You can find this in $SPLUNK_HOME/etc/instance.cfg
Using this approach we can migrate data from standalone instance to multiple instances. Given the sensitivity of the task as the ingestion on standalone instance is stopped during the process, a simple mistake can affect Splunk and since this process is not fully supported by Splunk, it is recommended to contact Splunk-certified Professional Services Consultants to complete the data migration.
Also read: Understanding Splunk Architectures and Components

Dhruv Patel is working as a Senior Software Engineer at Crest Data Systems. He has 3+ years of experience in technologies like Splunk, Docker, AWS, etc. He is a Splunk Certified Architect and AWS Certified Solutions Architect. He currently works as Site Reliability Engineer leading a team to manage 24×7 Splunk operations. He holds a Bachelor’s degree in Computer Engineering from Gujarat Technological University, India.